测试了一下,卧槽,真的有用。以后就专门设计硬件优化吧。
基础知识
我们知道,volatile修饰的变量可以在线程间保证可见性和预防指令重排等,所以在一些情况下,我们可能要对指定的变量添加volatile修饰。在极端的情况,我们可能定义如下多个连续的volatile修饰的变量:
package com.example.demo;
public class Test {
volatile long a;
// long p2;
// long p3;
// long p4;
// long p5;
// long p6;
// long p7;
// long p8;
volatile long b;
// long bp2;
// long bp3;
// long bp4;
// long bp5;
// long bp6;
// long bp7;
// long bp8;
volatile long c;
// long cp2;
// long cp3;
// long cp4;
// long cp5;
// long cp6;
// long cp7;
// long cp8;
volatile long d;
// long dcp2;
// long dcp3;
// long dcp4;
// long dcp5;
// long dcp6;
// long dcp7;
// long dcp8;
public static void main(String[] args) throws Exception {
Test obj = new Test();
Thread t1 = new Thread(()->{
for (int i = 0 ; i < 500000 ;++i) for(int j = 0; j < 50 ; ++j) ++obj.a;
});
Thread t2 = new Thread(()->{
for (int i = 0 ; i < 500000 ;++i) for(int j = 0; j < 50 ; ++j) ++obj.b;
});
Thread t3 = new Thread(()->{
for (int i = 0 ; i < 500000 ;++i) for(int j = 0; j < 50 ; ++j) ++obj.c;
});
Thread t4 = new Thread(()->{
for (int i = 0 ; i < 500000 ;++i) for(int j = 0; j < 50 ; ++j) ++obj.d;
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
t3.start();
t4.start();
t1.join();
t2.join();
t3.join();
t4.join();
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
上面代码启动四个不同的线程,分别操作a,b,c和d四个volatile变量,去掉注释后在我的电脑上(5600x)运行会快大概20倍。这是因为volatile变量在发生修改时,为了保证可见性,会通知其他正在读取或修改该变量的线程,同步线程空间。这里你可能会问,四个线程修改的不是不同的变量吗?不是应该不会互相影响吗?按理来说t1线程修改a变量没有必要去通知正在修改b变量的t2线程啊。
这里要引出缓存行的概念了,CPU在读取变量时不是一个字节一个字节的读取的,也就是说CPU读取变量时是按块读取的,比如说上述代码,t1线程在操作a的时候,可能已经将a,b,c和d四个变量全部读取到了线程空间,这样一来当然要互相通知啊。
所以,为了解决这种没有必要的通知,我们可以在变量间加入padding,使不同变量在线程空间中隔离开来。那么,缓存行的大小到底是多少呢?
我们可以通过CPU-z这样的工具进行查看:
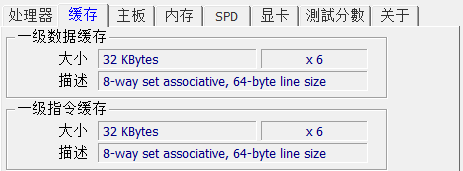
可以看到,我的CPU的缓存行是64byte,这也是为什么上面代码补充7个padding。
更多语言测试
上周培训的时候测试了其他语言的性能,结果发现都有很大的性能提升。
由于测试的时候发现GO竟然比C++快,太不可思议了,于是尝试用C,这个实际上C和C++性能相差不大(C++用的是std::thread,其底层还是pthread)。这里C和C++的编译均采用默认GCC/G++.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
struct A{
long a;
long p2;
long p3;
long p4;
long p5;
long p6;
long p7;
long p8;
long b;
long bp2;
long bp3;
long bp4;
long bp5;
long bp6;
long bp7;
long bp8;
long c;
long cp2;
long cp3;
long cp4;
long cp5;
long cp6;
long cp7;
long cp8;
long d;
long dcp2;
long dcp3;
long dcp4;
long dcp5;
long dcp6;
long dcp7;
long dcp8;
} a;
void f(){
for(int i = 0 ; i < 500000 ; ++i)
for(int j = 0 ; j < 500; ++j) ++a.a;
}
void g(){
for(int i = 0 ; i < 500000 ; ++i)
for(int j = 0 ; j < 500; ++j) ++a.b;
}
void u(){
for(int i = 0 ; i < 500000 ; ++i)
for(int j = 0 ; j < 500; ++j) ++a.c;
}
void v(){
for(int i = 0 ; i < 500000 ; ++i)
for(int j = 0 ; j < 500; ++j) ++a.d;
}
int main(){
pthread_t thr[4];
pthread_create(&thr[0],NULL,f,NULL);
pthread_create(&thr[1],NULL,g,NULL);
pthread_create(&thr[2],NULL,u,NULL);
pthread_create(&thr[3],NULL,v,NULL);
for(int i=0; i<4; ++i) pthread_join(thr[i],NULL);
return 0 ;
}package main
import (
"fmt"
"sync"
"time"
)
type A struct {
a int64
pa1,pa2,pa3,pa4,pa5,pa6,pa7 int64
b int64
pb1,pb2,pb3,pb4,pb5,pb6,pb7 int64
c int64
pc1,pc2,pc3,pc4,pc5,pc6,pc7 int64
d int64
pd1,pd2,pd3,pd4,pd5,pd6,pd7 int64
}
var a A
func main() {
var wg sync.WaitGroup
//
//a.a = 1
//a.b = 1
//a.c = 1
//a.d = 1
start := time.Now() // 获取当前时间
// 问题不大 仅仅测试而已
wg.Add(1)
go func(){
for i:=0;i<500000;i++{
for j:=0;j<500;j++{
a.a++
}
}
wg.Done()
}()
go func(){
wg.Add(1)
for i:=0;i<500000;i++{
for j:=0;j<500;j++{
a.b++
}
}
wg.Done()
}()
go func(){
wg.Add(1)
for i:=0;i<500000;i++{
for j:=0;j<500;j++{
a.c++
}
}
wg.Done()
}()
go func(){
wg.Add(1)
for i:=0;i<500000;i++{
for j:=0;j<500;j++{
a.d++
}
}
wg.Done()
}()
// 这里有可能有问题
wg.Wait()
elapsed := time.Since(start)
fmt.Println("该函数执行完成耗时:", elapsed,a.a,a.b,a.c,a.d)
fmt.Println(a.d)
}C VS GO
下午的时候突然想到GCC编译还有优化选项的,果然开启优化后C的速度就超过GO了。
gcc main.c -std=c99 -O1 -pthread现在问题又来了,Java就算了,为什么GO也比C慢这么多。
参阅了网上的资料后,发现确实如此。



1 条评论
cocofhu · 2021年7月24日 上午3:20
嘟嘟嘟
评论已关闭。